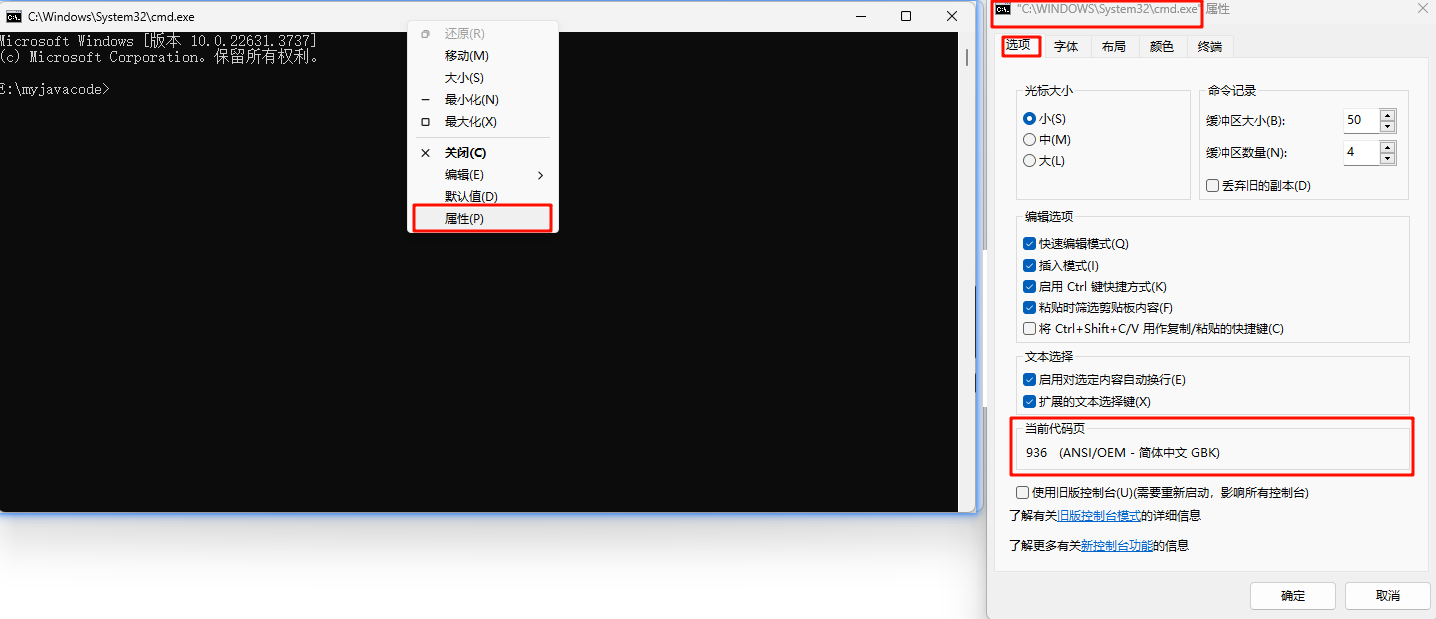
在前一篇封装的文章内说到,面向对象程序三大特性:封装、继承和多态。那么接下来讲下面两个特性:继承、多态。
继承
继承这里的概念,就是字面意思,核心就是要搞清楚“父与子”。
为什么会用到继承?试想一下,我们现在要做一个教务管理系统,那么其中的用户角色有学生、老师、管理员,我们肯定是对这些角色分别建一个类,不过每个类中有诸如头像、姓名、年龄等这些每个都相同的成员变量,那么我们真的要这三个类内每个人都写一遍这些吗?其实不然,我们想到这些人都是用户,那么我们可以做一个用户的父类,让这些角色的类进行继承。所以,用继承的作用是通过共性抽取去提高代码的复用和方便后续维护。比如,如果我发现每个人都漏了一个成员,那么我可以加到这些子类关联的父类里;如果我要给学生的类加特有的学号和班级的信息,那么我直接在学生子类内加即可。
不过继承还有个作用就是实现多态,将在下文讲到。
extends 关键字
用于表示两个类间的继承关系是 extends 关键字,上述说明的代码如下(适当简化)。
// User.java文件
public class User {
public String name;
public int age;
}
// Teacher.java文件
public class Teacher extends User {
public int teacherId;
public String teachClass;
}
// Student.java文件
public class Student extends User {
public int studentId;
public String class;
} extends 关键字前面是子类(也叫派生类),后面是父类(也叫基类、超类)。同样的,成员方法也可以从父类继承到每个子类。
但是注意的是,Java不支持多父对一子的继承,即用代码表示如 public class Teacher extends User, TestUser
同时也不推荐出现超过三层的继承关系,不要有太复杂的继承关系。
子类访问父类
当子类继承了父类后,可以访问父类中的成员变量和成员方法等。如果是子类成员变量和父类成员变量不同名的情况下,是可以直接访问的。如果是出现同名的情况下,优先访问子类的成员变量。但是如果子类中访问了父类不存在成员变量,显然会编译报错。由此,子类对成员变量的访问可以认为是就近原则。
对于成员方法,也是如此。不过之前在类和对象中讲过,方法是能重载的(即方法名相同,参数列表和返回值不同的情况),那么如果父类和子类间的相同方法名的时候,可以按需要选择适合的方法访问。
成员方法中还有构造方法,要注意的是,应该是先调用父类的构造方法,再调用子类的构造方法。(简单去记,那对于现实中同样是这样“先有父才有其子”的关系)
既然基本上是子类成员优先,但是我如果即希望保留子类的成员,又想访问父类的成员呢?
super 关键字
super 可以认为是子类内从父类继承来的这块内存的内存的标识。那么就需要用到 super.成员 来在子类去访问父类的成员了。注意只能在子类的非静态成员方法中去访问父类的成员。
上面对于构造方法的说明中,我们明白需要先在子类对象构造完成之前,帮助父类对其中的成员进行构造。那么此时调用父类的构造方法就需要super() 。如果父类的构造方法是含有参数的,super() 括号内也只管填入参数列表即可。这个语句只能放在子类的构造方法的第一行,且不能和 this 同时出现。
// User.java文件
public class User {
public String name;
public int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
// Student.java文件
public class Student extends User {
public int studentId;
public String gender;
public Student(String name, int age, int studentId, String gender){
super(name,age);
this.studentId=studentId;
this.gender=gender;
}
}真的需要每次我们都要在子类的构造方法内第一行写 super() 嘛?其实如果在父类只有一个不带参数的构造方法的情况下,会自动在子类的构造方法第一行前有隐含的 super(); 调用。
我们会发现这个表达和我们之前文章中讲的this引用时很相似,我们对比下:
| 表达方式 / 作用 | super | this |
关键字.成员 | 子类中访问父类的成员 | 访问当前类对象的成员 |
关键字() | 子类中访问父类的无参构造方法 | 访问当前类对象的无参构造方法 |
同样,也有很多共同点:比如第二种表达方式都只能放在方法内的第一行,只能用来访问非静态成员方法和字段。
代码块执行顺序
我们知道静态是依赖于类的,所以静态代码块 static {} 是在类加载时执行,即最先被执行的,在 父类和子类的关系上也是如此,父类的静态代码块先于子类的代码块的执行。
还有种代码块叫实例代码块,是直接用 {} 括起来的(也不带访问修饰限定符)。比如我们无法在类中直接放赋初值语句等,但是可以放到实例代码块内。实例代码块的执行优先级是高于构造方法的执行,原因是给对象分配内存的时候,接下来就是实例化的过程:实例变量→实例代码块→构造方法,而且重要的是实例代码块可能依赖于对象实例变量的状态,但不一定需要构造方法提供的具体参数。
对于继承关系的两个父子类,那么父类的实例代码块执行,再父类构造方法执行完后才能去执行子类的实例代码块,再执行子类的构造方法。上文我们提到还有静态代码块,如果父类和子类均有静态代码块的话,则顺序依次是:父类静态代码块→子类静态代码块→父类实例代码块→父类构造方法→子类实例代码块→子类构造方法。(顺序简析:父子类被加载,静态代码块先父后子执行,父子类对应的对象被创建后需要实例化,先父后子完成实例化过程)
protected 访问修饰限定符
| 范围 | private | 默认 | protected | public |
| 同个包同个类 | ✅ | ✅ | ✅ | ✅ |
| 同个包不同类 | ✅ | ✅ | ✅ | |
| 不同包内子类 | ✅ | ✅ | ||
| 不同包非子类 | ✅ |
经过本文说明,到这儿就能明白这里的子类是什么意思了。如果被 protected 修饰了成员变量,成员方法等表示要么只能在同一个包中的类中进行访问,要么在不同包中只能通过在继承关系上的子类对象来访问。
形象地说,protected 就可以看作是一个被保护的“家”,这个房间是家里的人“父与子”还有有关系的亲戚都可以使用的,外部的人如果没有与家中的人有亲属关系是不能访问的。
结合上一篇文章,我们基本讲完了四大访问修饰限定符,什么时候该用哪种呢?
我们希望类要尽量做到“封装”,只暴露出必要的信息给类的调用者,而无需关心其内部实现。所以在设计类的时候应该尽可能的使用比较严格的访问权限。
final 限制继承
final 关键字去放在成员变量的访问修饰限定符前,代表这个变量值已经完全确定,此时表示常量。
final 关键字去放在类的访问修饰限定符前,代表这个类无法继承了。如我们常用的 String 类。
组合
组合也是像继承一样可以代码复用的一种方式。组合是指在新类中创建现有类的对象。
// 假如这是一个APP的组成
// 导航条
class NavBar{
}
// 顶部banner
class Banner{
}
// 内容元素
class Content{
}
public class App {
// 这部分就是实现了组合
private NavBar nav;
private Banner banner;
private Content content;
}需要区分的是,组合表示出来的是一种「has-a」的关系,而继承则是「is-a」。组合是类A 拥有 类B 的一个实例,A类包含了B类的实例作为其成员变量,来实现“整体”与“部分”之间的关系;继承是子类 是 父类的一种特殊类型,比如上文中Student是User中的一种特殊用户。
而且一般推荐是:能用组合的尽量用组合。因为使用继承,不可避免地打破了封装性(违反OOP原则),迫使开发者去了解父类内的细节,而且父类的更新可能导致bug,对程序维护来说并不有利。
多态
多态也是字面意思, 不同的对象会有不同的状态。比如同样是叫声,猫叫和狗吠肯定不一样。
要实现多态有三个必要条件,缺一不可:在继承体系下、子类必须要对父类中的方法进行重写、通过父类的引用调用重写的方法。所以多态的变化是根据方法里传递不同类的对象的时候来体现的。
方法的重写
介绍
之前的文章中有提到过方法的重载,是指同个方法名但是不同的参数列表、返回类型和访问修饰符,这使得同一个方法名可以根据参数的不同实现不同的功能。
那么,方法的重写是发生在子父类间的同名、非static、非private修饰、非final修饰的方法中,当子类重新定义父类中的方法时,会覆盖父类的方法实现。
还需要注意:返回值、形参、方法名都是要和父类中的一致(外壳不变,核心重写);子类重写方法的访问权限不能⽐⽗类中被重写的⽅法的访问权限更低;在父类被static、private修饰的方法、构造方法都不能被重写。
在IDEA中,对于重写的方法可以使用 @Override 注解来显示指定,而且IDEA可以识别到这个注解去进行合法性校验。
综上,其实方法重载是一个类的多态性的体现,而方法重写是子类与父类的一种多态性表现。
避免在构造方法中调用重写方法
先说结论:用尽量简单的方式使对象进入可工作状态。尽量不要在构造方法内调用方法。
如果出现了构造方法内要调用的方法被子类重写了以后,我们走一遍流程就会发现bug:首先,在构造子类对象的时候,要优先构造父类对象由此就会调用父类的构造方法。父类的构造方法内会调用被子类重写的方法,但由于子类对象还未完全初始化,此时调用该方法可能导致异常或未定义行为。
向上转型
父类引用指向子类对象,就是表达为 User stu = new Student("nibbles",18,123456,"男"); stu 是 User 类型的引用变量其指向了其子类 Student 类型的对象。
这样进行向上转型了虽然无法使用子类的特有的方法,但是可以在方法传参的场景下可以把形参作为父类型引用去接收任意类型的子类对象,也可以作为方法返回值来返回子类对象(如 return new Student(...))。
如果说有两个父类引用都指向了子类对象,都对父类里的一个方法进行了重写。那么调用该方法时,实际执行的是子类中重写后的方法,这就是动态绑定机制,也是多态性的体现。
向下转型
在上述向上转型后,如果还想调用子类特定的方法,此时就需要把父类引用再还原回子类对象。
package cn.nibbles.animaldemo;
// Animal.java
public class Animal {
public String name;
public int age;
public void eat(){
System.out.println("eating");
}
}
// Cat.java
public class Cat extends Animal{
public Cat(String name, int age) {
this.name = name;
this.age = age;
}
public void mew(){
System.out.println("cat mewing");
}
}
// Dog.java
public class Dog extends Animal{
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
public void bark(){
System.out.println("dog barking");
}
}
// Test.java
public class Test {
public static void main(String[] args) {
Cat cat = new Cat("a cat" , 1);
Dog dog = new Dog("a dog" , 2);
Animal ani = cat;
ani = dog;
// 模拟父类引用变量多次更换对象
// cat = (Cat)ani;
// cat.mew();
// ClassCastException异常
dog = (Dog)ani;
dog.bark();
// 正确向下转型到原子类对象
}
}
但是,这里就出现个问题,如果我忘记了之前父类型的引用变量对应的子类型的话,那程序就会出现ClassCastException异常,可以使用 instanceof 运算符在类型转换前进行检查,避免此类异常的发生。
那么上面的示例代码中向下转型的部分可以改写为:
// Test.java
package cn.nibbles.animaldemo;
public class Test {
public static void main(String[] args) {
Cat cat = new Cat("a cat" , 1);
Dog dog = new Dog("a dog" , 2);
Animal ani = cat;
ani = dog;
// 模拟父类引用变量多次更换对象
if (ani instanceof Cat){
cat = (Cat)ani;
cat.mew();
}
// ClassCastException异常 -> 检查不通过、不报异常
if(ani instanceof Dog){
dog = (Dog)ani;
dog.bark();
}
// 正确向下转型到原子类对象 -> 正常执行
}
}
圈复杂度
核心思想是用代码中的控制流图环路数量(即独立路径数)来衡量一个程序的复杂度。圈复杂度反映了代码中“决策点”的数量,也就是需要做判断的地方(如 if、while、for等)。值越高,说明代码的逻辑分支越多,测试起来更复杂,也更难维护。
而多态就是可以减少圈复杂度,不必写那么多分支结构。可扩展能力也更强,能直接新增一个新的类去继承父类即可。