
前言
上线即爆火,DeepSeek-R1正面临烦恼:每天涌入的海量用户让服务器不堪重负,频繁的卡顿和崩溃让无数人空有AI入口,却难触技术前沿。
这背后折射出的,正是AI技术从实验室突破到大规模应用必须跨越的体验门槛。
本文将探寻让不时罢工的DeepSeek-R1(后文简称R1)这一前沿AI得以重新动工的自救方案。
自救方式
目录:
- 当搜索遇上R1
- API集合云服务平台
- 本地部署
当搜索遇上R1
这种方式优势在于可以联网,首先由AI搜索自带的模型去搜到最新的网站,然后从这些网站中获取最新的数据!
但是其内置的R1模型是不是满血版(即MoE混合专家模型+671B+64Ktokens)有待考证。
秘塔AI搜索 – R1
声称使用的是“满血版R1”,有长思考链路的特征,且输出速度较快;
需要注意的是一次搜索,不支持上下文和追问

纳米AI搜索 – R1
360和DeepSeek-R1联手提供了一个高速专线以及满血版。均能长思考,不过思考能力有差异。支持上下文和追问,国内访问通畅
- 360高速专线,模型为32B,搭建于化为 910B GPU服务器
- 满血版,即671B,搭建于化为 910B GPU服务器。需要花费20纳米每次提问

赚纳米的方法:
- 每日水提问(去底部导航栏第一个“AI搜索”那儿搜),提问一次+10纳米,一次即可
- 每日连签(点击头像下方进入签到页面,每日+10纳米,7日连签共得160纳米)
- 邀请好友+100 纳米
Perplexity Reasoning – R1
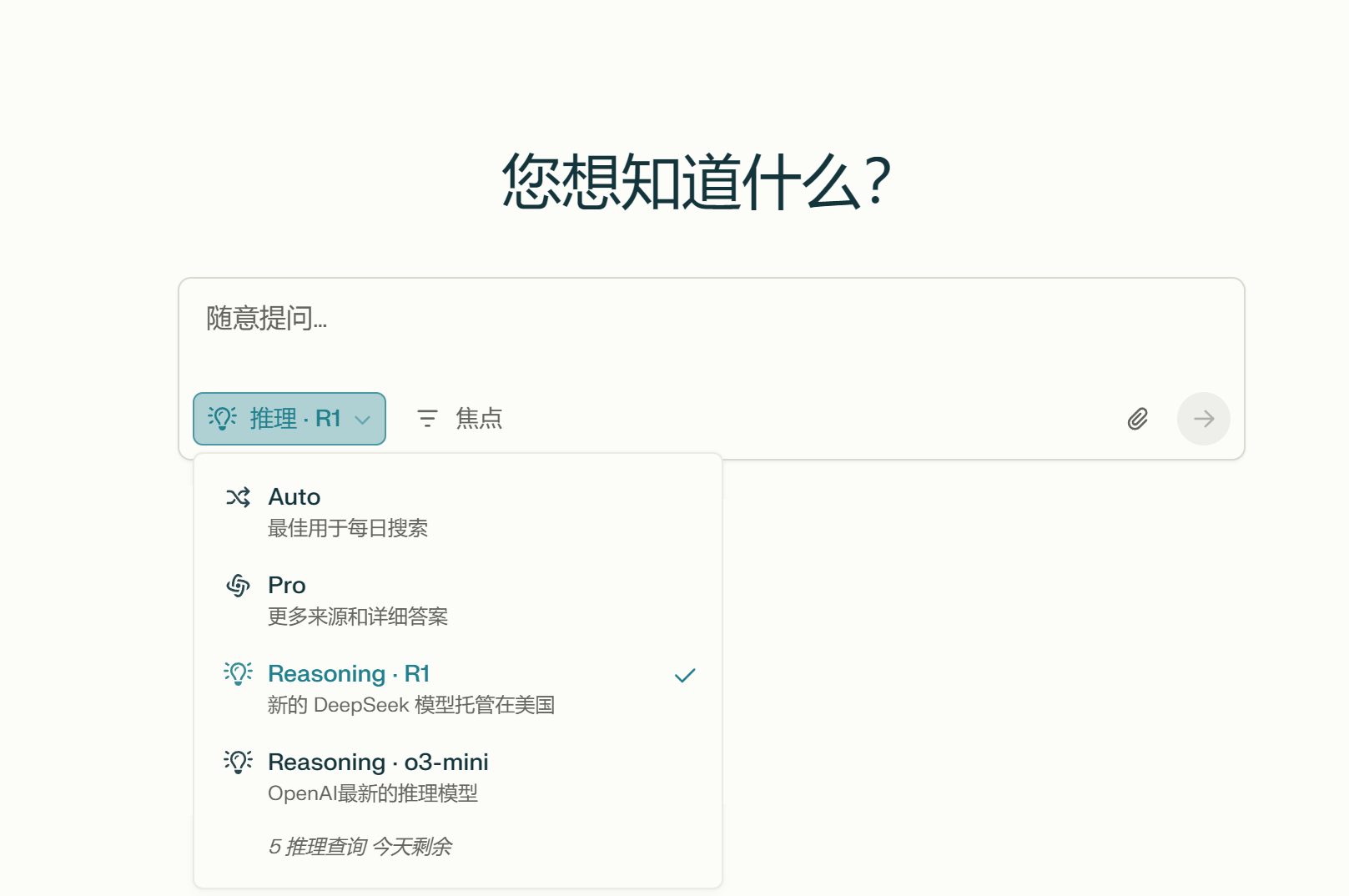
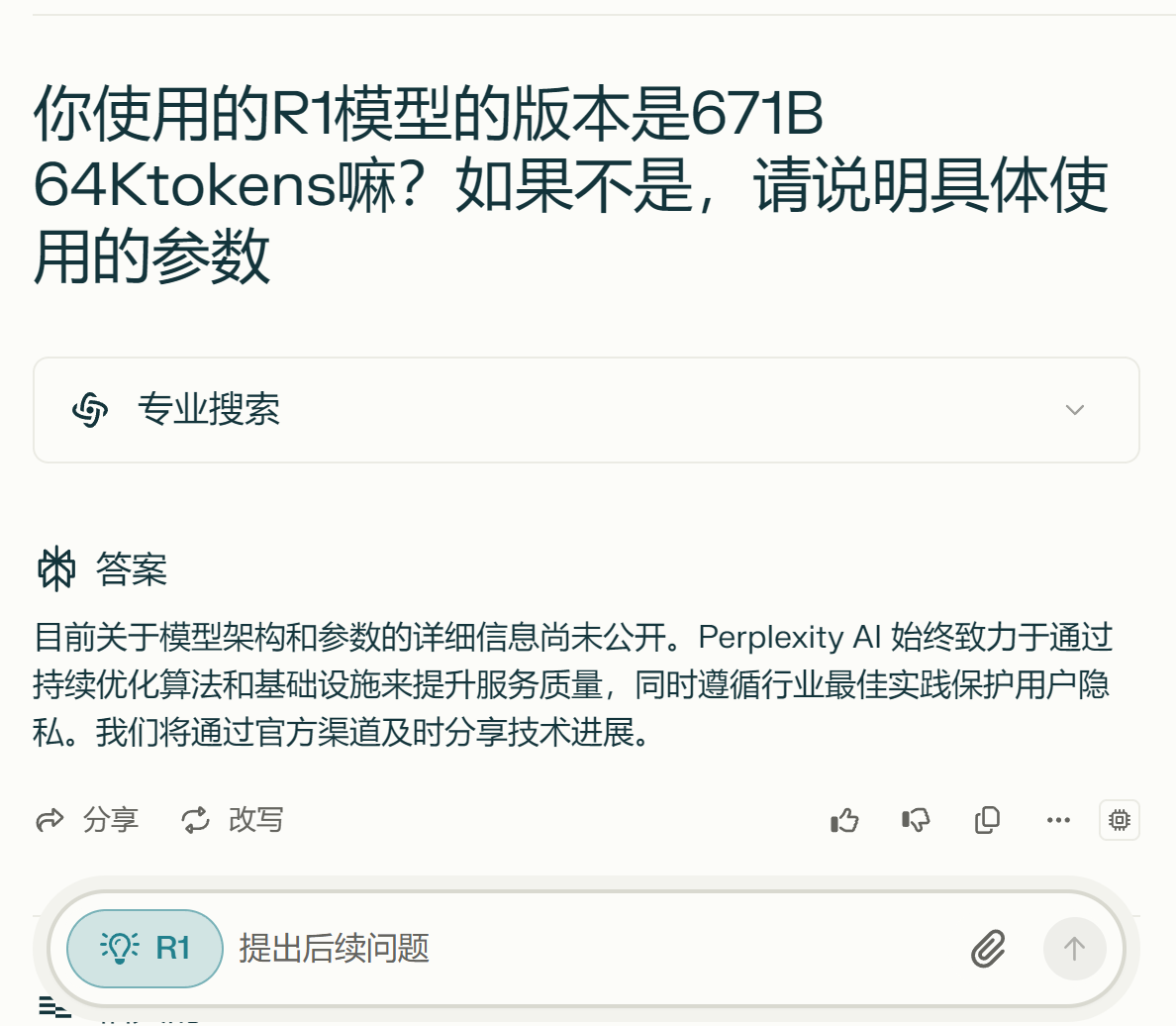
根据perplexity的help center中的文章《About the R1 model used for Pro Search on Perplexity》 是把R1开源模型完全部署在美国,但是具体使用的版本暂无公开,可见后图。
支持上下文和追问,但是对国内部分网站访问会受阻(比如知乎)。推理内容有时是英文、有时是中文,一般如果思考语言和提问语言相同(比如都是中文)呈现结果可能会让人满意些。
API集合云服务平台
这种方式优势在于参数透明地使用不同版本的R1,但是痛点在于无法联网。模型内为静态数据还只停留在某一时间点。
但是已经可以应对很多场景了,比如翻译、码代码、营销运营等。
下面这些都可以添加到列表里哦~
SILICONFLOW 硅基流动
R1模型调用每次对话根据可读取上下文数会消耗一些tokens,这已经可以用比较久了。
并且模型跑在华为云昇腾云服务器,更佳稳定快速。
官网:https://cloud.siliconflow.cn
邀请码:h77yf43s
从我的网站这个链接进入可以让你拿到平台内初始14元即2000万tokens哦!好东西要一起分享~
AiHubMix
有多种R1模型可同站切换。稳定推荐使用aihubmix-DeepSeek-R1 是在azure上开源部署,目前比较稳定;响应比较慢,但是输入输出比官方高,最高输入128k;还有deepseek-ai/DeepSeek-R1
官网:https://aihubmix.com/
GPTAPI
R1模型调用价格相比官方API原价低了一半。效果同官方,但不支持并发(也就是不能多次同时请求,比如接入沉浸式翻译;但是普通聊天的可以)
官网:https://www.gptapi.us/
平台内初始$0.2
Nibbles AI
新的自建代理平台,即将上线,敬请期待!不会让好人失望,助大家一起赶上AI革命的浪潮!
未来会发文通知,请关注“尼布技术志”公众号接受文章推送哦~
AGICTO
公司运营,稳定,调用费用较贵,模型为满血版。
客户端对接平台API
目前已知可以用的AI客户端见下表:
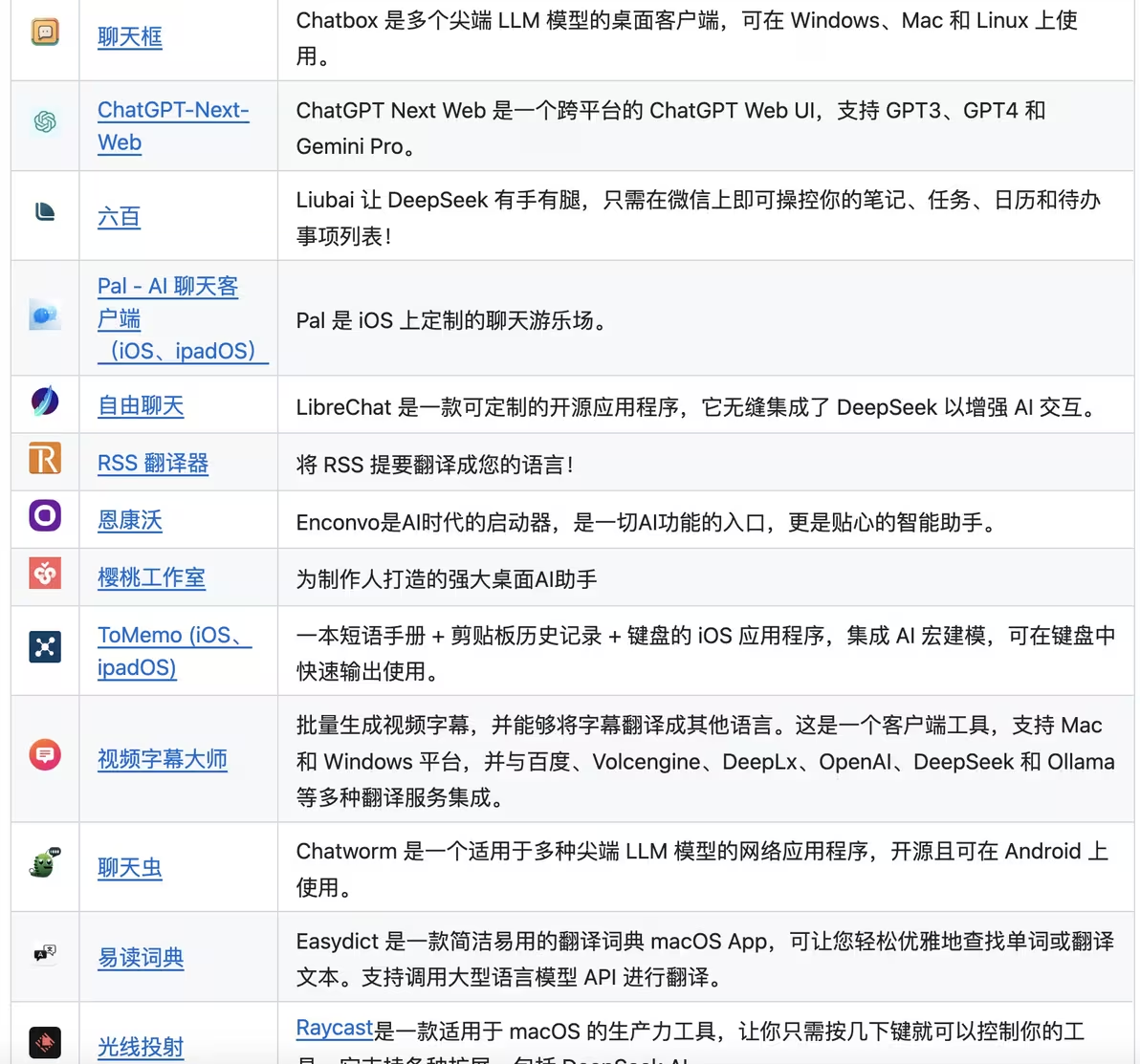
这个表有经过翻译工具的转换,所以部分名称请自行对应到最后一列的说明中的英文名称。
接下来教程以“SILICONFLOW 硅基流动”平台为例,客户端以电脑端的Cherry Studio(樱桃工作室)和跨平台的Chatbox(聊天框)为例。
平台API获取
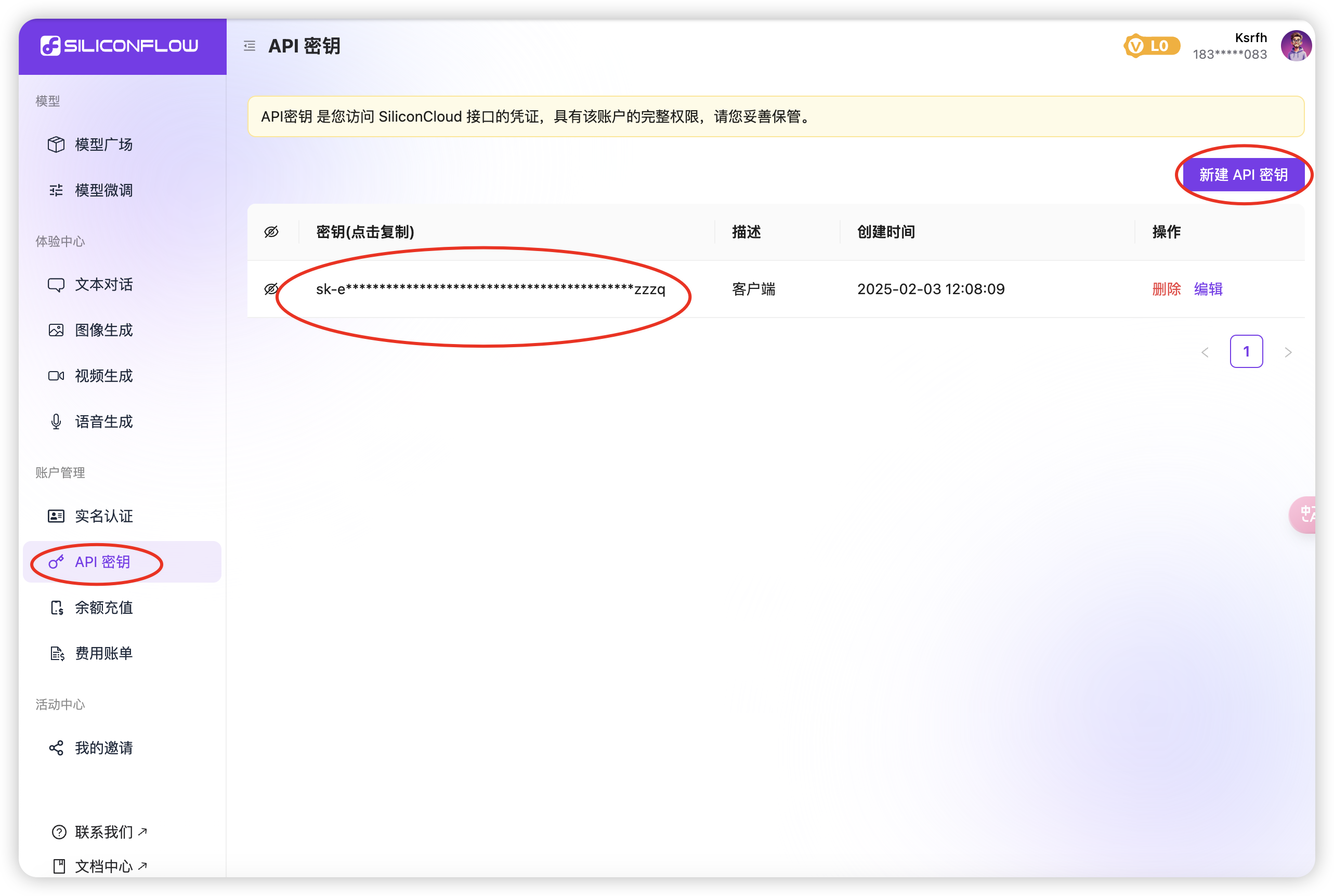
1.创建 API 密钥:平台注册登录后,点击左侧「API 密钥」→「新建 API 密钥」。
2.选择R1模型:点击左侧「模型广场」,选择你需要的模型→点击「复制模型名称」。
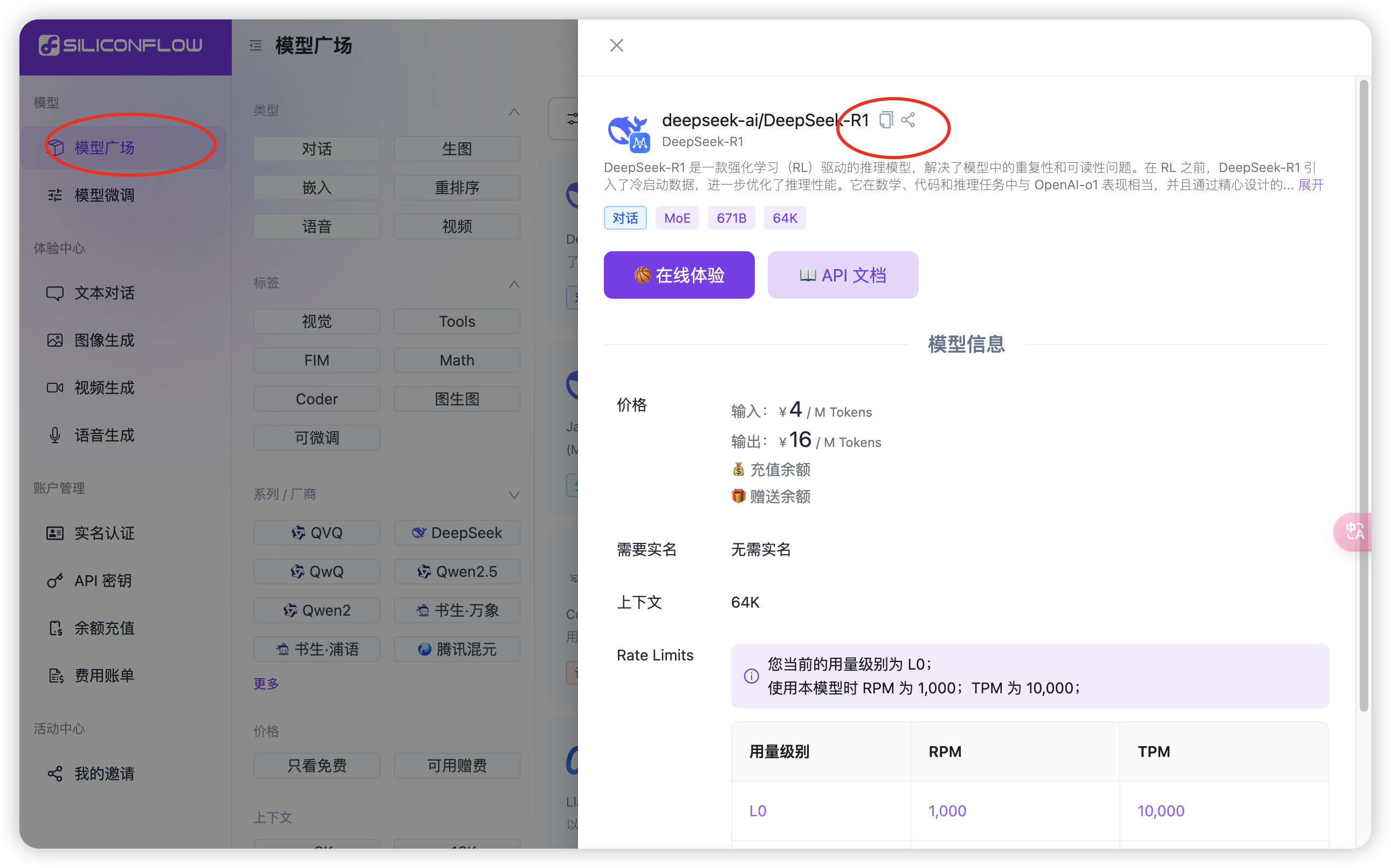
Cherry Studio
3.下载客户端:官方网站为https://cherry-ai.com/,(2025/2/4)最新版本号为v0.9.17
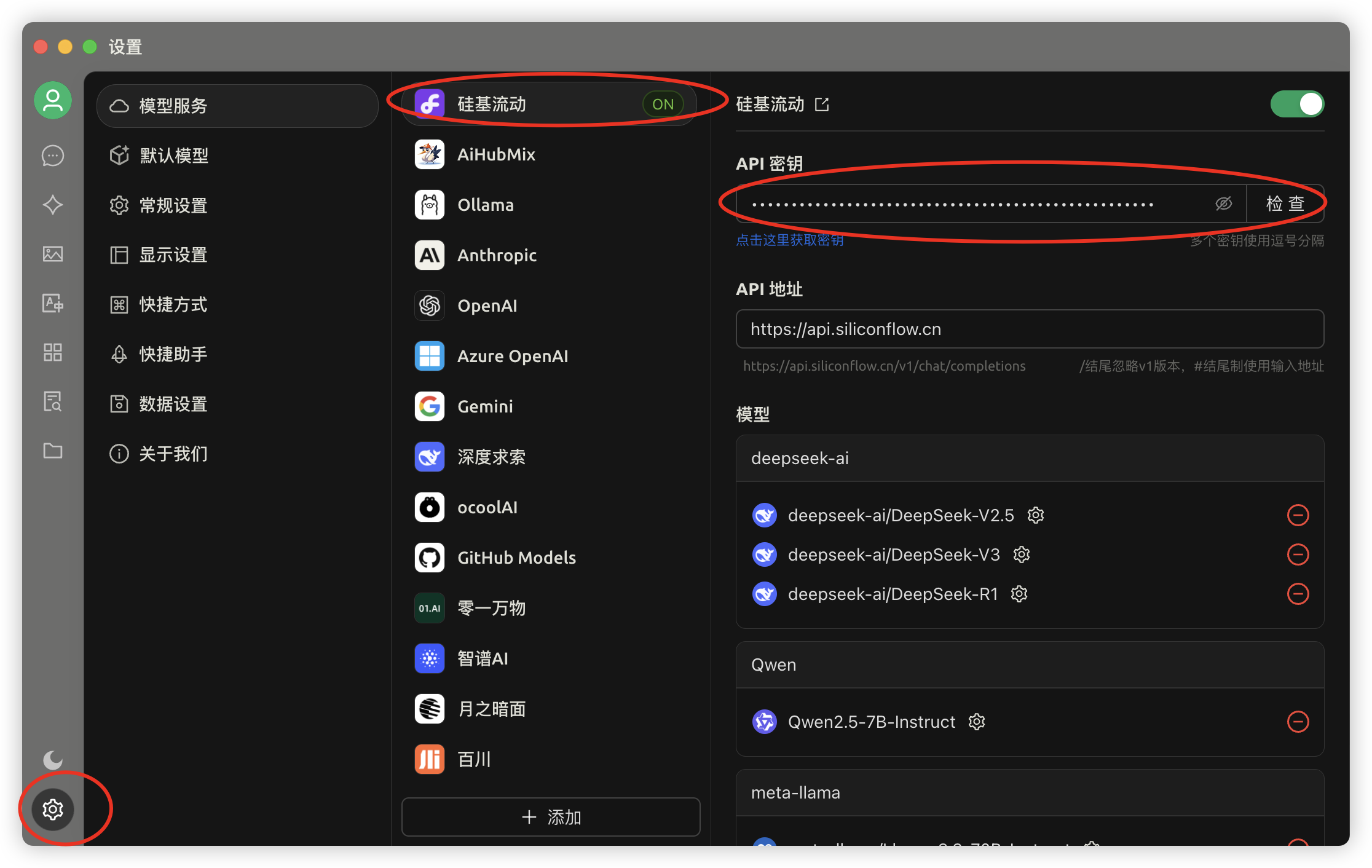
4.配置客户端:打开客户端→点击左下角「设置」→选择已有的「硅基流动」→粘贴刚创建的 API 密钥。
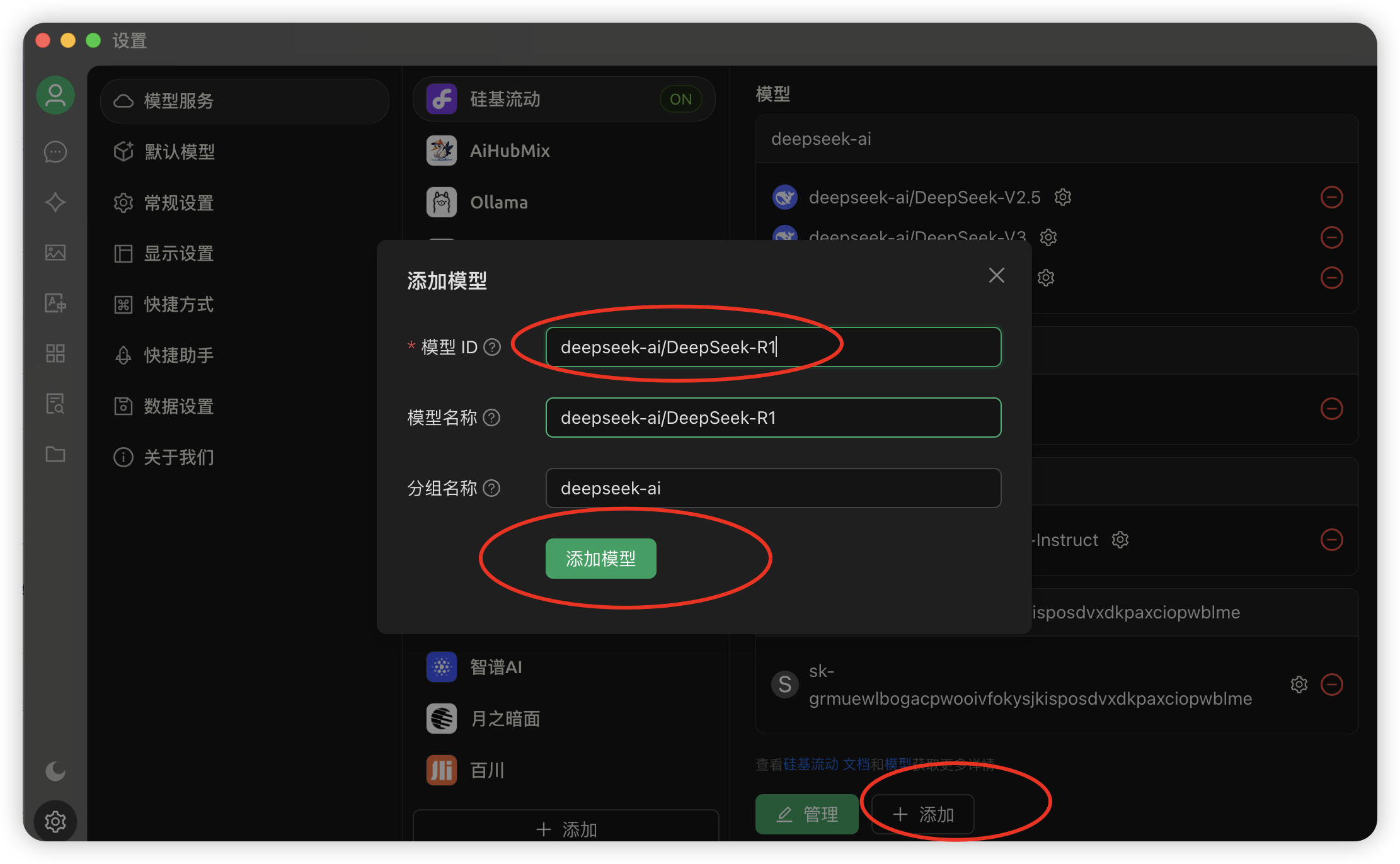
5.添加模型:拉到最下方→点击「添加」→粘贴刚复制的 模型名称→点击「添加模型」。直接把之前复制过的模型名称粘贴到「模型ID」部分,后面两个会自动填充。
6.开始对话:回到主界面→点击上方「切换模型」→选择你添加的模型→开始畅聊!
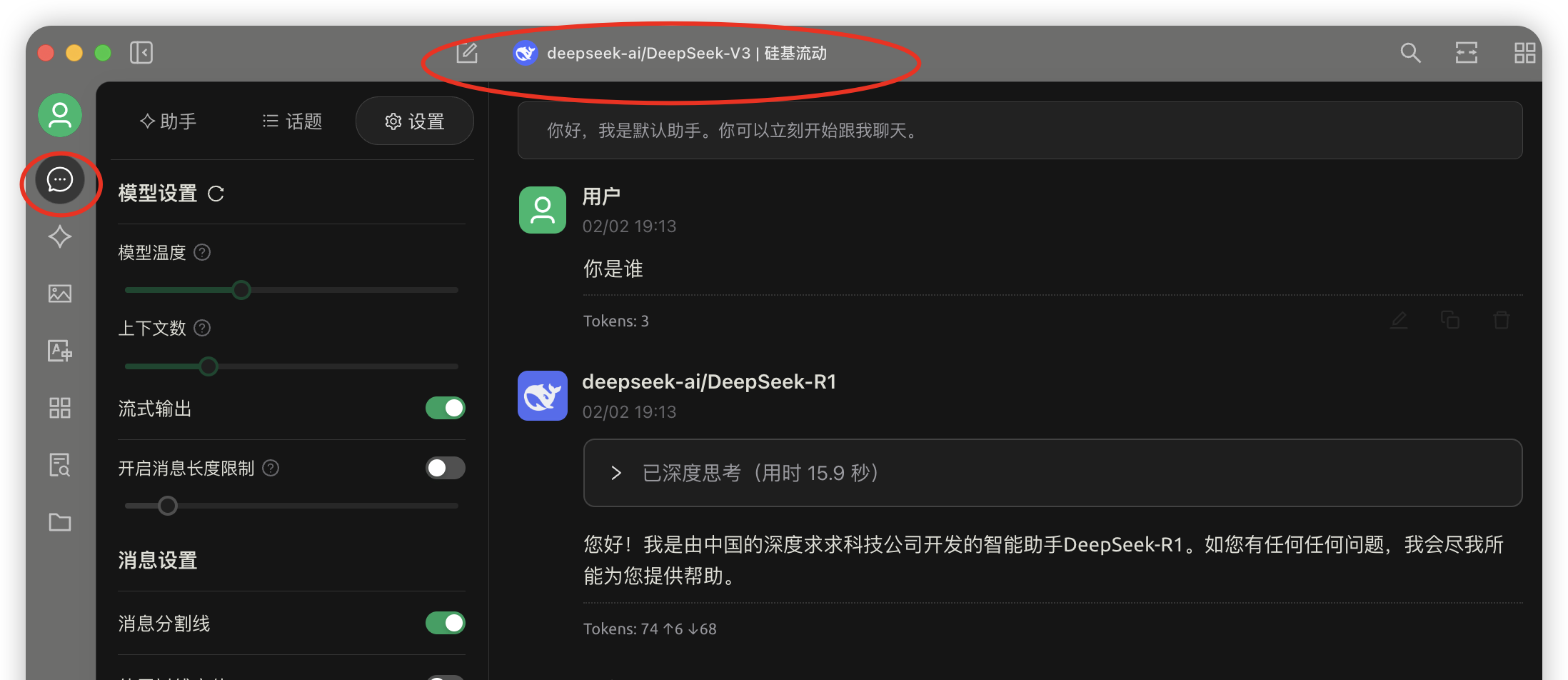
Chatbox 各端
网页端入口:https://web.chatboxai.app/
Windows PC下载地址:https://chatboxai.app/install_chatbox/win64
手机端苹果用户请前往 美区的Apple Store 和安卓用户请去 Google Play 上下载(官网下载apk文件部分用户反应打开一直处于loading…)
3.界面语言:(手机端需要先点击左上角)左下角的「Setting/设置」点击进入→点击「DISPLAY/显示」→在「Language/语言」中选择「简体中文」,后面字体大小和主题都可以自己调。
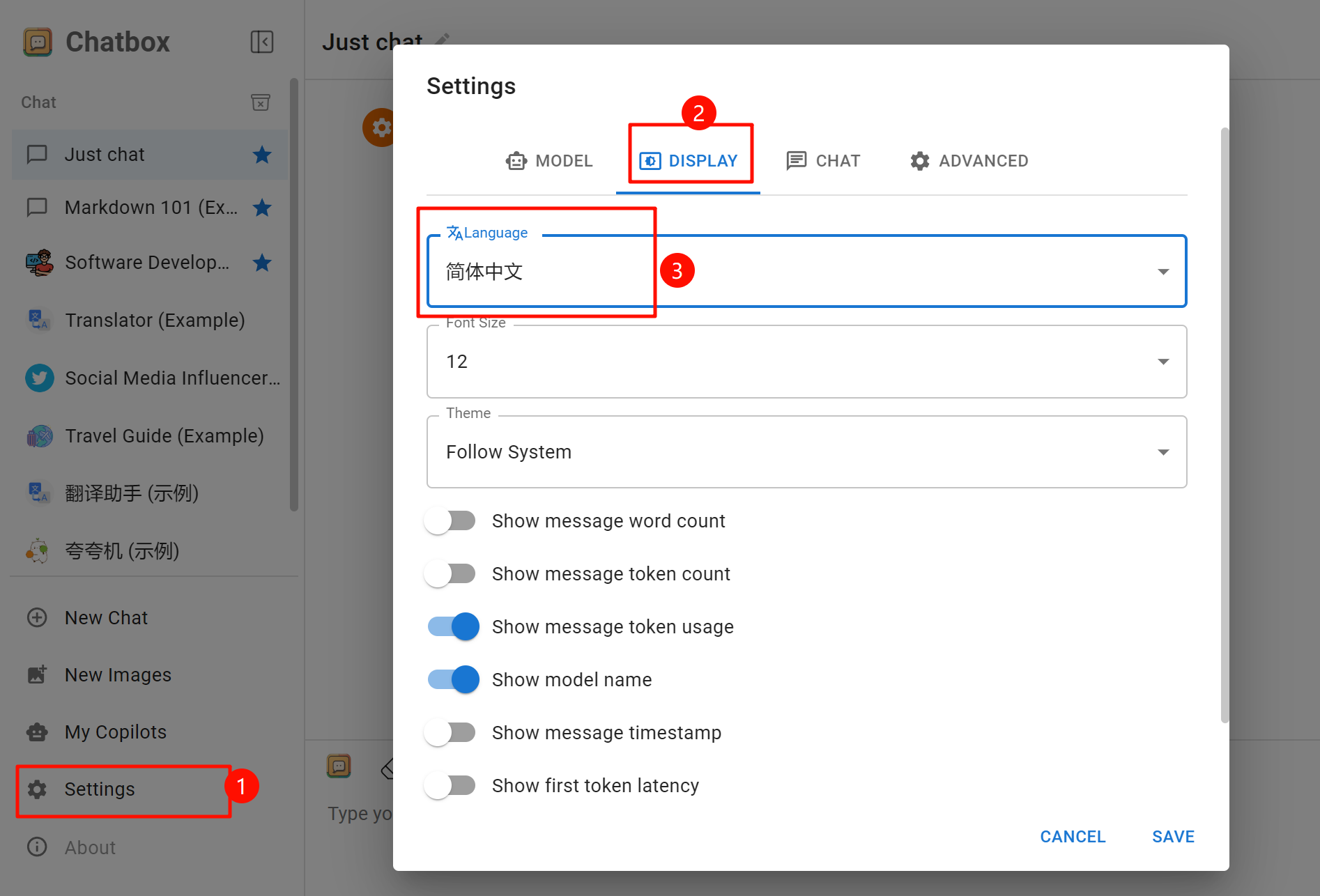
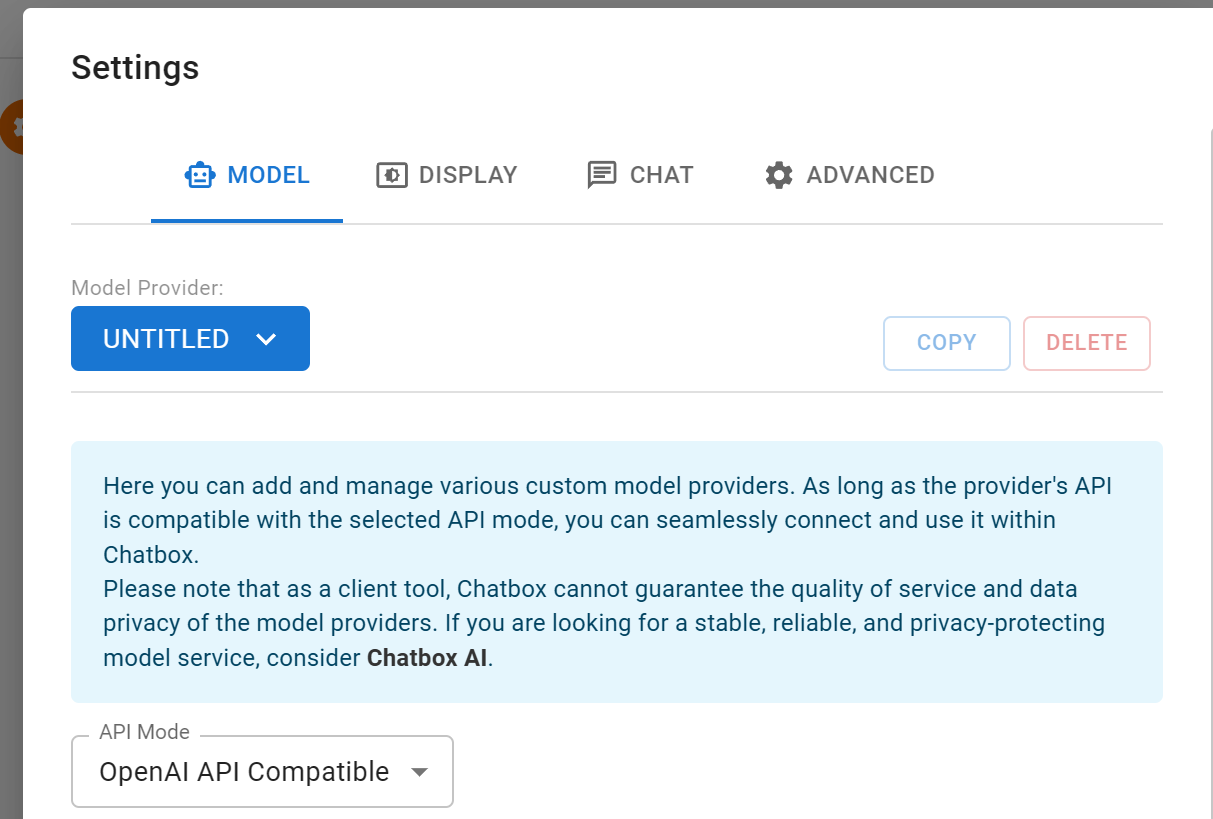
4.配置客户端:点击「MODEL/模型」→在「Model Provider/模型提供方」中选择「UNTITLED」
(简中界面根据位置判断哪个)
根据如下红框中的参数配置!
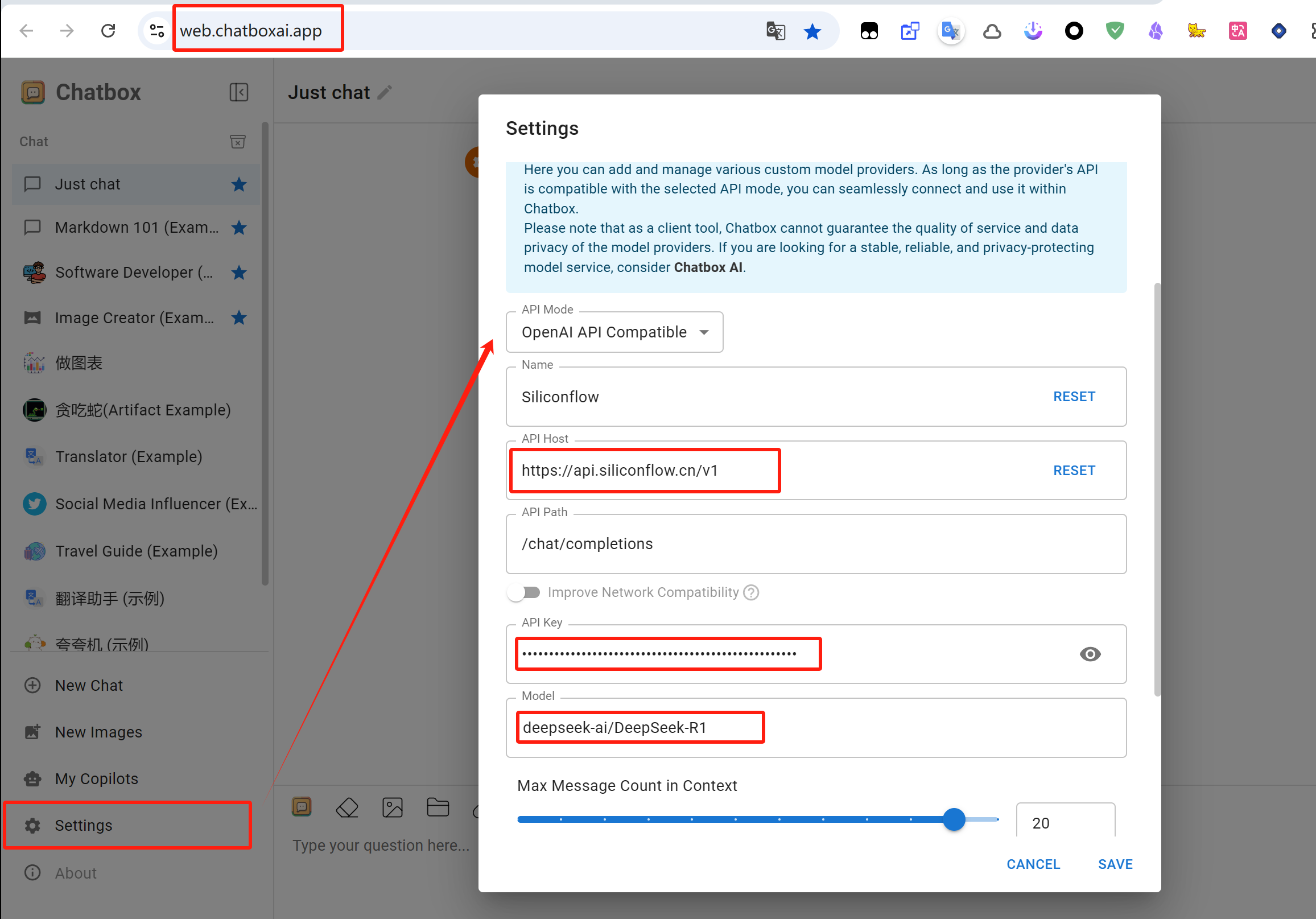
各端的界面都是类似的,可以类比使用。
以后切换都需要在「Model Provider/模型提供方」中选择。如果要添加多个平台,就点击「Model Provider/模型提供方」→「添加自定义提供方」后保存。
如果是网页版使用,清理了浏览器的Cookie会导致原模型设置的丢失。
其他端只要不卸载即可~
本地部署
低配电脑请自动跳过本节,用上述两种方式自救。
手机应该是没法部署的,因为有的手机厂商为了手机AI已经有在本地跑一个轻量的模型了。
电脑推荐配置
内存RAM大于等于16G,专用GPU显存不低于4G即可带动模型。
但是满血版就不要想了,需要使用机房带专业卡的GPU服务器,本地部署只是为了处理一些简单的工作。
专业显卡(如 NVIDIA A100)是专为高性能计算(HPC)、人工智能(AI)和科学计算设计的图形处理器。此类显卡售价较为昂贵,且售卖对象以企业为主。
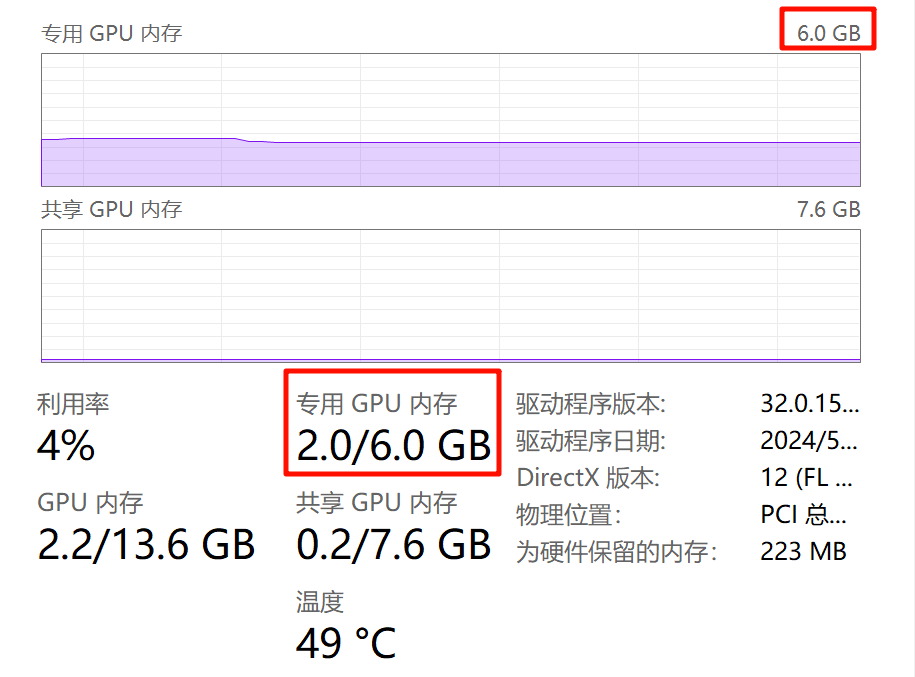
专用GPU显存查看方式
- Mac电脑可以自己看「关于本机」中的找到内存,显存要切换到「显示器」→跟在显卡型号后面的几个GB就代表显存大小,比如
Radeon Pro 5500M 8 GB是8G显存。- Windows 11 PC右键底部任务栏,选择「任务管理器」,切换到「性能」(从上往下数第二个),选择GPU1(一般GPU0是集成显卡),往下拉,比如笔者这个就是6G显存。
NVIDIA显卡还需安装下CUDA:https://developer.nvidia.com/cuda-downloads
模型选择与下载
请选择文件体积小于自己显存大小的模型,略大一些的虽然也能跑,但是速度会慢很多。
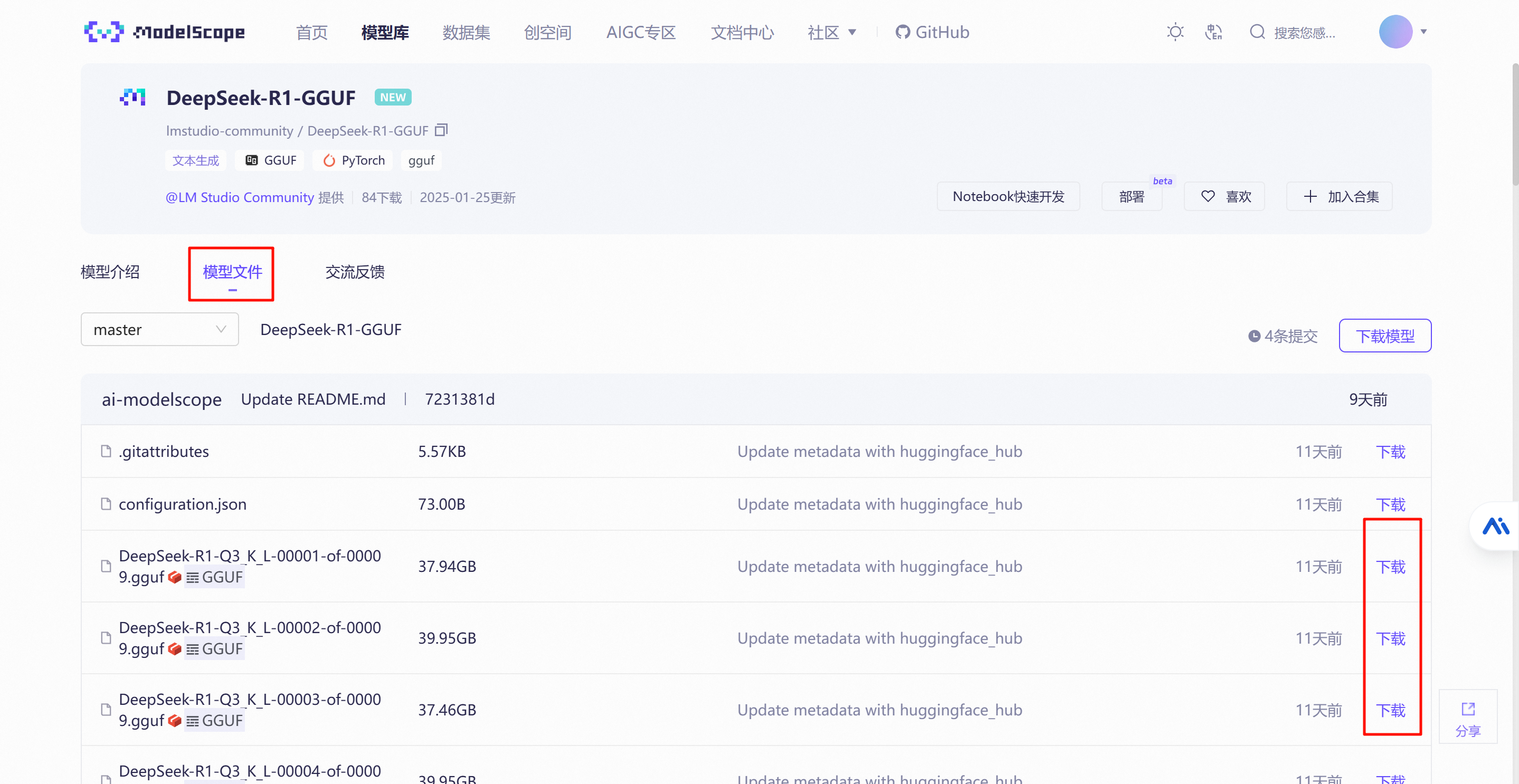
模型镜像下载地址:https://www.modelscope.cn/organization/lmstudio-community
上面这个地址更适合中国网络环境,可以搭配IDM等下载器。
诸如HuggingFace等其他外网社区的话,有能力的人可自行去下载使用。
部分模型参数说明:
qwen2和llama指的是模型的架构。- 名称中带
Distill即表明此为蒸馏模型,蒸馏的目的是使原模型更加轻量、高效。
接下来推荐使用LM Studio软件对话,命令行教程我也放一下。
LM Studio 带图形界面对话
软件下载地址:https://lmstudio.ai/
安装好后,
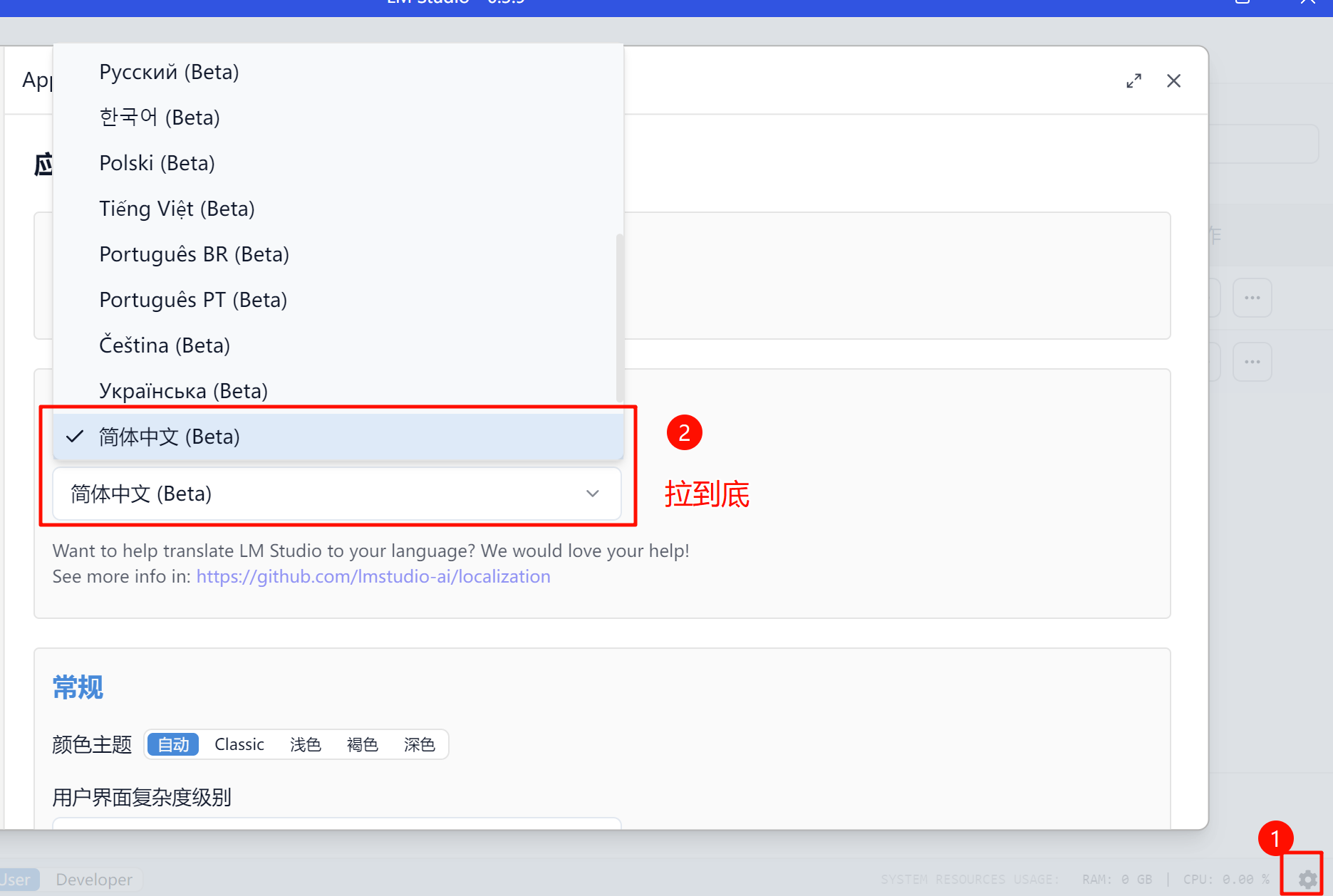
修改界面语言:
点击右下角的⚙按钮,「Language」中选择「简体中文(Beta)」
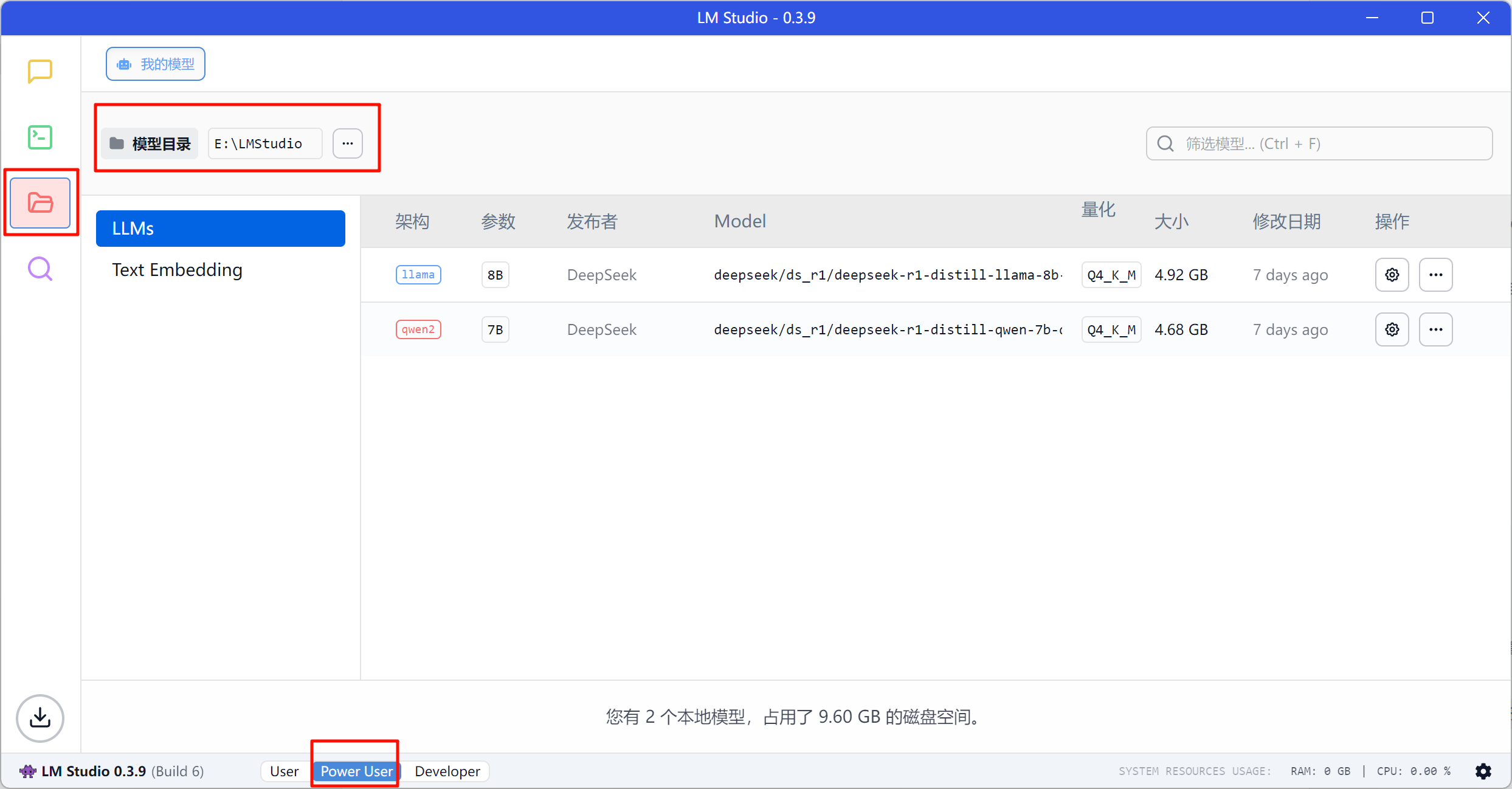
修改模型目录:确认底部「Power User」界面,后点击从上往下数第三个文件夹图标,看到旁边的「模型目录」
在C盘外新建一个专门存放模型文件的目录,哪个盘大就在哪个盘下建立。(如果你C盘留得足够大空间那无所谓) 目录中不要有中文和特殊字符。
进入目录,创建文件夹并拖入模型,这步需要注意细节,否则识别不出来!
需要创建两层文件夹,第一层名称代表发布者,第二层名称代表模型类别,如下笔者设置的:
E:\LMStudio-test>tree
卷 Files 的文件夹 PATH 列表
E:.
└─DeepSeek
└─R1GIF动图演示:
回到软件的界面发现模型装载了那就成功了。回到聊天界面,在顶部选择刚刚的模型即可开始了。

为了生成速度快,可调的参数有:
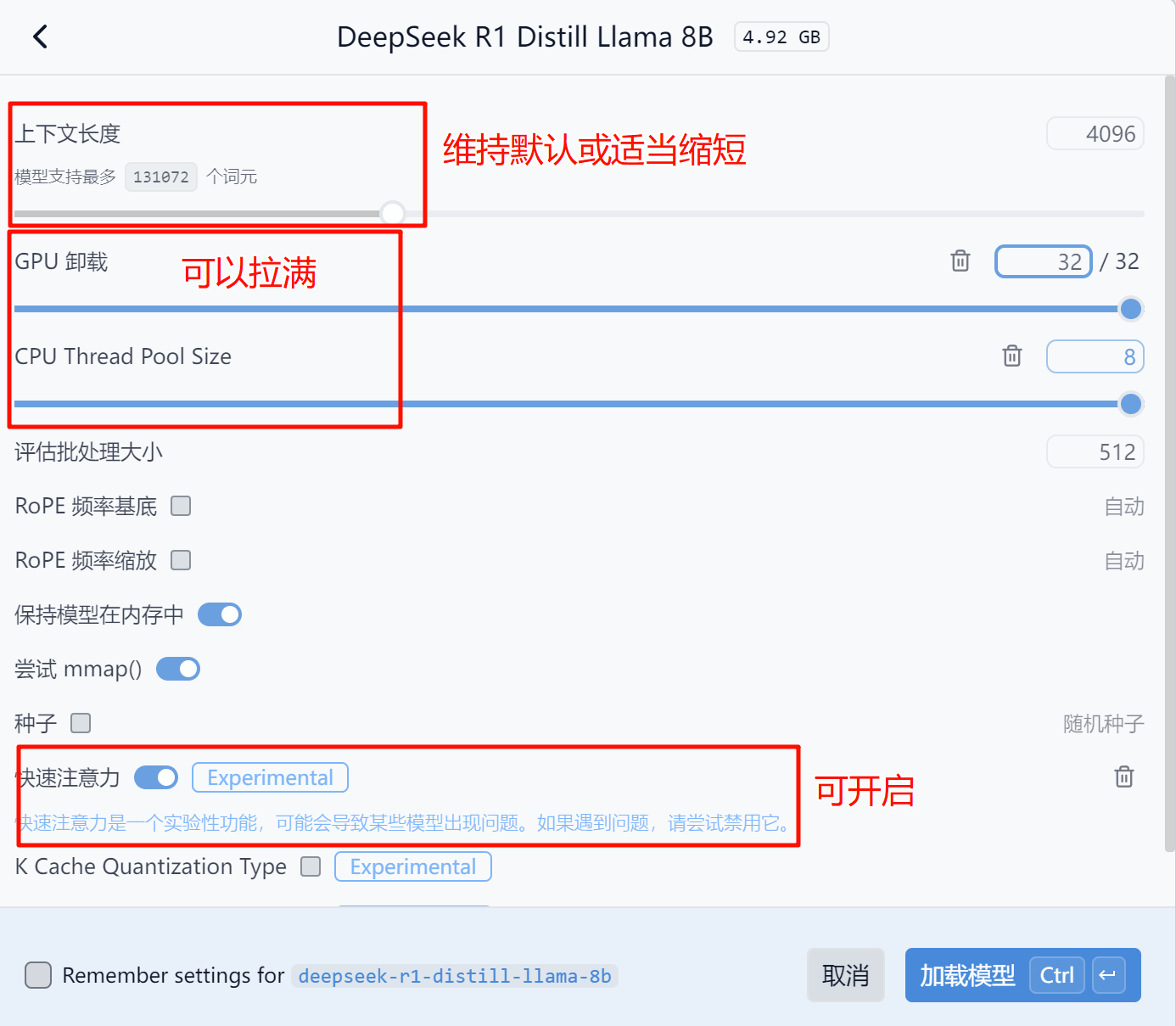
命令行对话
Ollama官网:https://ollama.com/
确保电脑上已经装了Ollama,判断方式为cmd/终端输入ollama,输出如下即可:
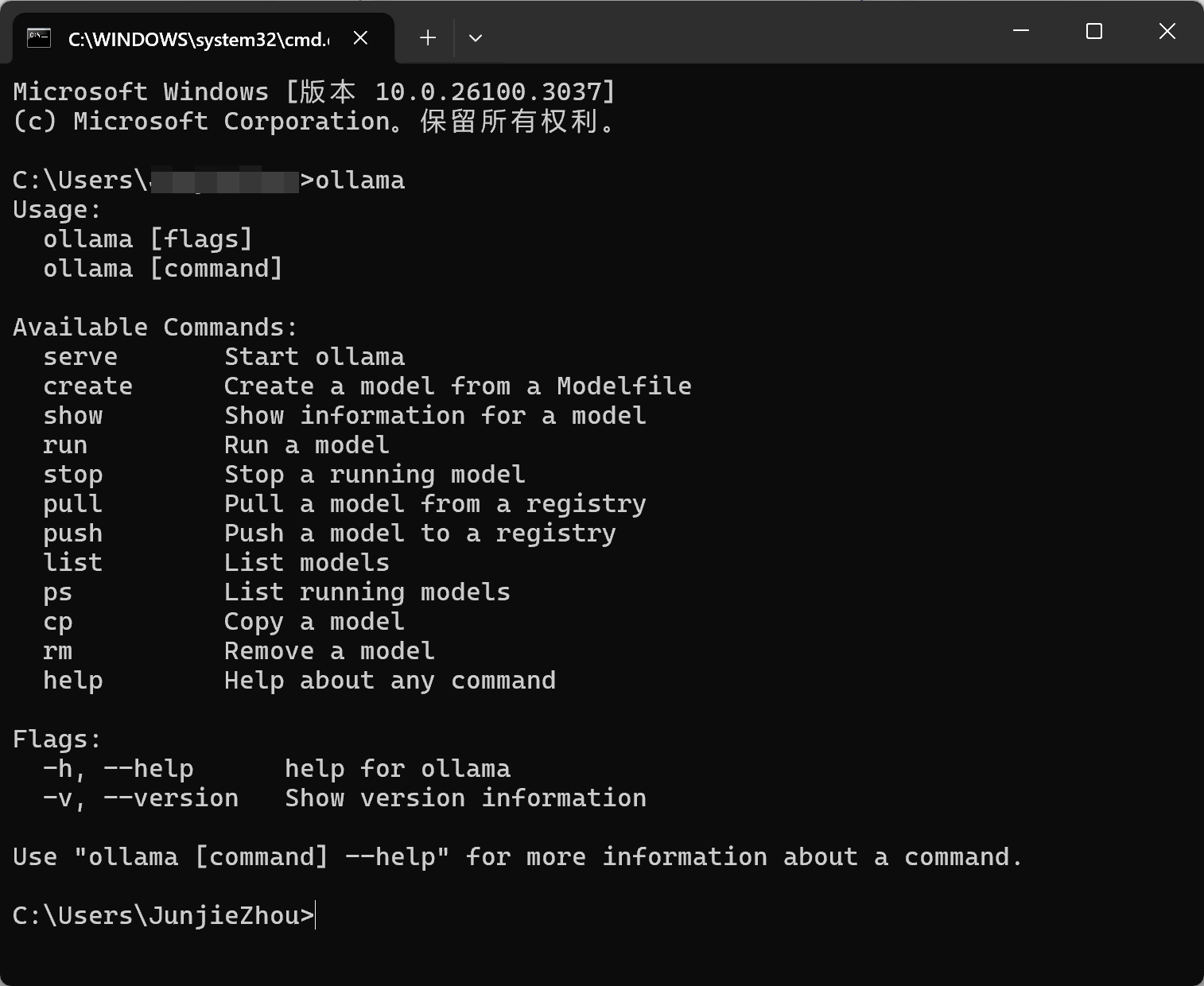
有外网条件的人可以官网顶部搜索框点击后选择deepseek-r1

往下拉找到符合自己配置的模型复制命令到cmd/终端,安装。
如果跟着上面步骤已经下载了模型GGUF文件(我是存在E:\Ollama\DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf),可以通过文件安装:
- 创建 Modelfile:新建一个文本文件
Modelfile(文件名可自定义,无后缀),内容如下:
FROM "E:\Ollama\DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf"
# 可选参数调整
PARAMETER gpu_layers 20 # 根据显存容量调整(例如 RTX 3060 6GB 可设置 20 层)
PARAMETER num_ctx 4096 # 上下文长度
PARAMETER temperature 0.7 - 通过 Ollama 安装模型
ollama create my-mistral -f Modelfilemy-mistral是自定义的模型名称 - 运行模型以测试安装是否成功:
ollama run my-mistral
输入提示(如你是什么模型?)查看回复是否正常生成。(准确度不保证,有的时候DeepSeek自己还会把自己认成OpenAI的)
结语
推荐(同任务难度):含R1可联网的搜索 > API集合云服务 > 本地部署
本文基于中国网络环境,如果执意想用外网请注意流量的消耗!
「收藏」本博客不迷路,我们后续“Nibbles AI”很快把网站上线,会推送新的文章告诉大家调用哦!
属于AI新时代已来,你我皆是弄潮儿!
携手跃入智能浪潮,做未来领航者!
发表回复