
Data Analysis in Python : pandas module

与Excel处理区别
pandas模块主要用于数据的处理与分析,其提供的大量处理数据的函数和方法,能方便操作大型数据集。而Excel适用于小数据样本,且较为单一的功能需求。
数据维度区分
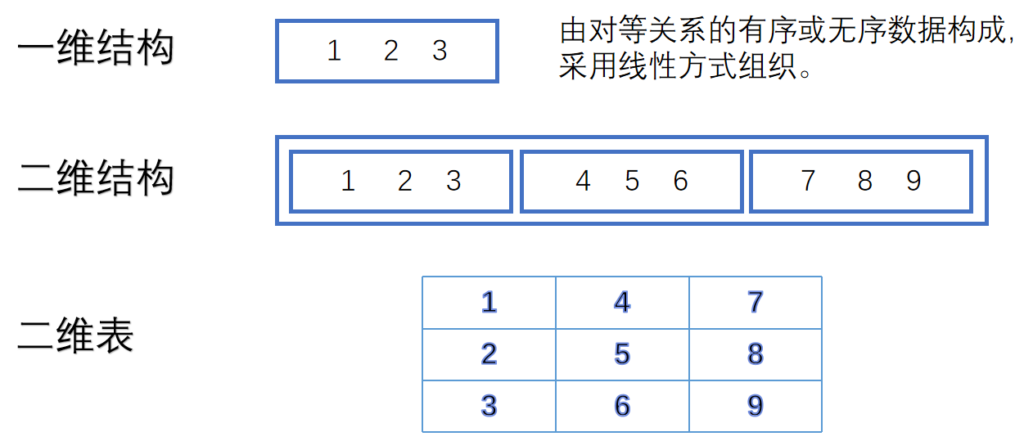
在pandas模块中主要的数据结构为Series(一维结构)和DataFrame(二维表)
模块安装与引入
最简单的方法即为下载Anaconda开发套件,这里面几乎集成安装了教材中能用到的所有模块!在未来会发布有关Anaconda的使用配置教程:https://nibbles.cn/tag/anaconda/
【官方网站下载】https://www.anaconda.com/download
pip命令安装 —— 一个Python包管理器,你可以使用它从 pypi.org 安装包
不过在此之前需要先换个源让我们下载速度更快
进入C盘的用户文件夹中的AppData\Roaming\pip目录,看到pip.ini内容,改为:
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/打开cmd,输入以下代码开始安装
pip install pandaspip方式,会默认帮你安装一些 NumPy 等其他可以搭配的包
进入shell解释器,输入 import pandas 引入模块语句(文件中的引入也应为此语句)。若已安装则不会返回任何提示,未安装会报 ModuleNotFoundError
在后文中我们使用如下引用约定(后文中引用模块时将会简写为as后的pd)
import pandas as pdSeries数据结构
创建
可以以列表和字典的形式形式创建,并以print()函数输出。输出中未指定索引index时默认为0起递增的整数。
并包含dtype说明对象类型(下例中为object,常见的还有int64、float64等)
列表中元素若有int和float交杂,则全部会转化为float;若存在字符串将会为object
s1=pd.Series(["N","I","B","B","L","E","S"])
print(s1)后多加一列表可指定索引(index=可以不加默认后一列表为索引),请注意前后列表元素的对应(即长度相同)。否则会报 ValueError : Length of values (<值元素长度>) does not match length of index (<索引元素长度>)
s2=pd.Series(["N","I","B","B","L","E","S"],index=["H","E","L","L","O","U","S"])
print(s2)当用字典创建时,它的键(key)会作为 index,值(values)为 data。
s3=pd.Series({"H":"N","E":"I","L":"B","L":"B","O":"L","U":"E","S":"S"})
print(s3)访问
以s2为例,分别输出index和values的值
print(s2.index) #运行结果:Index(['H', 'E', 'L', 'L', 'O', 'U', 'S'], dtype='object')
print(s2.values) #运行结果:['N' 'I' 'B' 'B' 'L' 'E' 'S']亦可以通过遍历输出(默认)values值。为了不使其自动按行输出,修改了end属性为空字符串
for i in s2: #默认输出values
print(i,end=" ")同样的可以修改s2为s2.index实现对索引的遍历
可以通过索引方式对其中的values查找操作,可以使用定义后的index或者默认index
print(s2["H"])
print(s2[0])如果索引相同的两个呢?
print(s2["L"])结果将会输出由index均为L的values组成的Series,同样会返回dtype
可以使用切片方式,但是需要注意区分使用指定索引和未指定索引时左右界能否取到的区别
print(s2[1:4]) #遵循正常左开右闭的原则
print(s2["E":"O"]) #index为E到O的均可以取到,则左右均闭筛选
筛选values为B的部分数据。注意中间的等于为判断操作,应当为双等号
print(s2[s2=="B"])DataFrame数据结构
DataFrame是一种类似于关系表的表格型数据结构。DataFrame对象是一个二维表格, 其中每列中的元素类型必须一致,而不同的列可以拥有不同的元素类型。可以看作共享同一index的多个Series的集合。
创建
同样的可以以嵌套列表和字典的形式形式创建,并以print()函数输出。输出中未指定index或columns时默认为0起递增的整数。不过相较于Series,DateFrame多了一个columns参数,输出时即为列标题
data=[["王静怡",34],["张佳妮",46],["李臣武",39]]
df1=pd.DataFrame(data,columns=["姓名","信息分数"])
print(df1)同样输出时有dtype说明数据类型,同样也可以指定index。
index注意需要与外列表长度对应,columns注意需要与内列表长度对应。
同样地,用字典创建时,它的键(key)会作为 index,值(values)为 data。
data={"学号":["01","02","03","04","05","06","00"],
"姓名":["小红","小明","小李","李华","张三","李四","缺考"],
"班级":[1,2,3,1,2,1,0],
"语文":[89,91,78,66,86,99,0],
"数学":[67,71,39,91,55,60,0]} #此处换行仅为了可读性与代码的美观
df2=pd.DataFrame(data)
print(df2)访问
以df2为例,同样的分别输出columns和values。若指定了index则也可输出对应值。
print(df2.columns) #输出:Index(['学号', '姓名', '语文', '数学'], dtype='object')
print(df2.values) #输出即为一个由每行数据组成的嵌套列表但如果为默认索引值将会输出其Range范围(如RangeIndex(start=0, stop=6, step=1))
同样也可以使用遍历输出index和(默认)columns,values输出将会是多个由每行数据组成的单列表
for i in df2.index:
print(i,end=" ")
for i in df2: #默认输出columns
print(i,end=" ")
for i in df2.values:
print(i,end=" ")可以使用索引方式对一列数据的输出,返回由该列数据与对应columns和index组成的Series对象。以下为两种均可使用的索引方式
print(df2["学号"])
print(df2.学号)如何输出多列数据呢?可以使用列表并其中包含columns值来实现输出(但输出非Series对象)
print(df2[["学号","姓名"]])输出行数据需要使用切片操作,其范围为index。若指定index则左右均闭。
print(df2[0:2])我们还可以通过内置的函数实现对前2行(head)和后2行(tail)的选取,返回Series对象
print(head(2))
print(tail(2))若需要对单个数据的访问可以使用at或者两次索引的方式。注意先后顺序:at后列表中共两个值,前为index,后为columns。而两次索引应当先对列索引后对行索引。
print(df2.at[0,"姓名"])
print(df2["姓名"][0])修改DataFrame对象中单一数据只能用两次索引方式,其实质仍为变量的赋值操作。但是如果索引值被整型数字修改了,那么将只能使用规定的索引值访问。
df1["姓名"][0]="wangjingyi"筛选
筛选找到语文成绩大于90分的同学数据,输出非仅仅只有语文数据,而是其他数据均有伴随着输出。注意中间的等于为判断操作,应当为双等号。
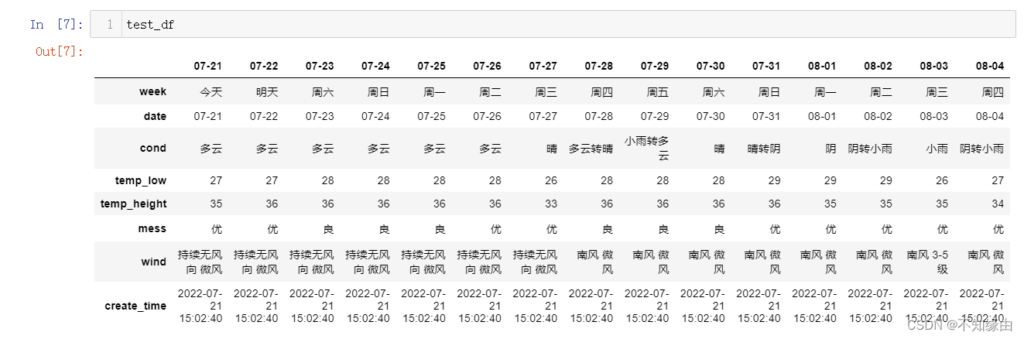
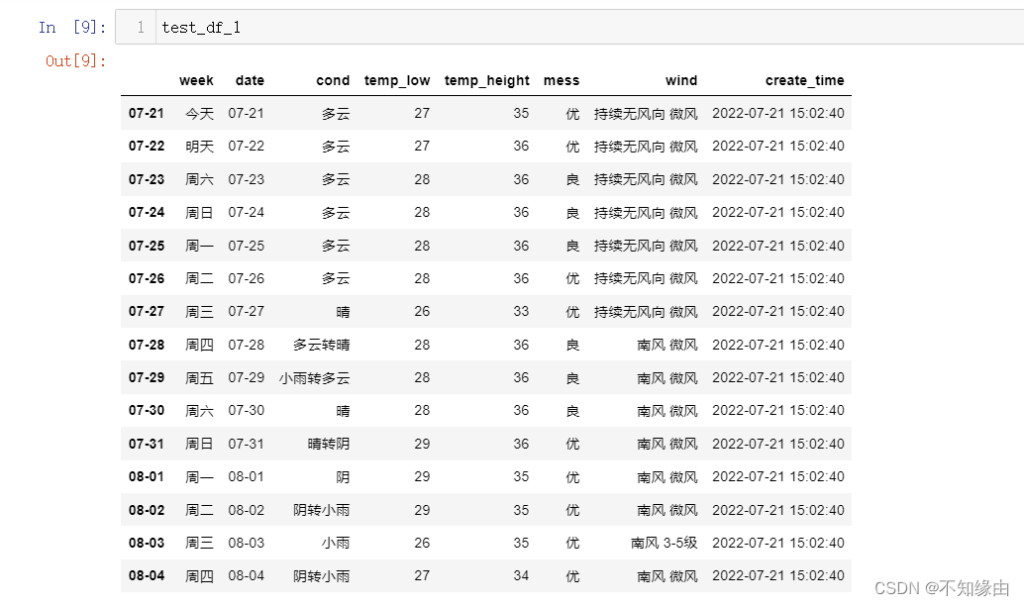
print(df2[df2.语文>90])行列转置
print(df2.T)对行列的交换,对df2原始二维结构未影响。见下图更好理解(可点击查看大图):
转置前
转置后
⭐ 定行列的axis
DataFrame相较于Series有了更多列,那么行列在pandas模块中如何实现区分呢?这里就不得不提一下axis这个几乎模块中每个操作或计算函数的均有的属性值,默认均为axis=0(若为0可省略)。
axis=0和axis=index等价,同样axis=1和axis=columns等价。
如图能更好地让你理解:
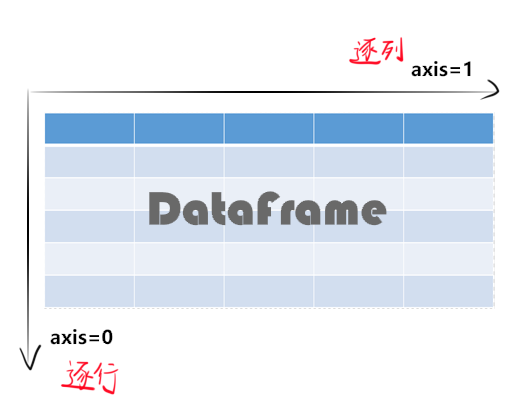
首先假设values区域数据类型相同均可以比较,当axis=0时,排序函数sort_values()会对此列每一行(逐行)数据之间进行比较,(设升序)在发现第一个值大于第二个值后交换此列中两行的位置,所以最终呈现出来的是列数据的位置改变;同理,当axis=1时,此行的每一列(逐列)数据之间进行比较,最终呈现的结果为行数据的改变。
同样为操作型函数需要区分的是,当axis=0时,删除函数drop()则是逐行寻找要删除的行数据然后删除,最终呈现是列数据的个数改变;反之,axis=1时删除函数则是逐列寻找要删除的列数据然后删除,最终呈现为行数据个数的改变。类似的,还有分组函数groupby()是沿着图示箭头方向逐行或逐列进行拆分分组。
假设values区域数据类型均为可计算的类型,计算型函数在axis=0时逐行进行计算结果反映为列的计算,axis=1时逐列进行计算结果反映为行的计算。
排序
df2_sorted=df2.sort_values("班级",axis=0,ascending=True)
print(df2_sorted)ascending属性值True为升序(默认),False为降序。
有时选择最高或最低的数据值时会采用先排序后切片的思路,如现需要列的最高的数据值会使列数据降序排序后使用[0]选取此列的第一个数据即为最高的数据值,代码实现见下:
df2_sorted=df2.sort_values("班级",axis=0,ascending=False,ignore_index=True)
#注意因为使用后文的[0]需要对索引进行刷新——使用ignore_index属性来实现
output=df2_sorted["班级"][0]
print(df2_sorted)
print(output)分组
df2_group=df2.groupby("班级",axis=0,as_index=False)
print(df2_group)as_index属性值True为作为索引(默认),反之为False时不作为索引。若例中改为as_index=True,当作为索引后就无法使用原来columns的索引(df2_group.班级)访问,而应为df2_group.index。
分组函数单纯处理不会有什么作用,也没有输出。所以一般与其他函数配合使用。
计算
| 函数名 | 功能解释 |
|---|---|
count() | 返回非空(空数据项表示为NaN)数据项数量 |
sum() | 求一列之和 |
mean() | 求一列的平均值 |
max() / min() | 求一列的最大值/最小值 |
median() | 求一列的中位数 |
std() | 求一列的标准差 |
axis=0)还有个聚合了上表一些功能的describe()函数,故名思意其能返回各列基本描述统计值,包含计数、平均数、标准差、最大值、最小值及 4分位差(其数值越小,说明中间的数据越集中;其数值越大,说明中间的数据越分散。)
分组加计算的应用实例 – 计算每班的语文平均分
df2_yuwen=df2.groupby("班级",as_index=False).语文.mean()
print(df2_yuwen)删除
df2_delete=df2.drop(6)
print(df2_delete)例中为删除index为6的行数据(默认axis=0省略)。但是值得注意的是,当我们此时再运行print(df2)会发现df2的数据并没有被更改,而是存到了新的df2_delete这个DataFrame对象中。同样有如此情况的还有append()追加这一函数。如何让这种函数直接更改原数据的值呢?这就需要指定属性inplace=True了(此参数默认为False,即不更改原数据)
其他操作
此处会列出考试中常见的代码,会慢慢补充
引入
read_excel() | 引入Excel文件(*.xlsx)中的数据为DataFrame对象 |
read_csv() | 引入CSV文件(*.csv)中的数据为DataFrame对象 |
删除异常
dropna() | 删除空值 |
duplicates() | 删除重复项 |
本文帮到你了吗?如果帮到了您,那就是我不断发文的动力!可以留个言,亦或是点点![]() 扫码到爱发电赞助我一下吧~
扫码到爱发电赞助我一下吧~
发表回复